
Databricks is a Unified Data Analytics Platform created by Apache Spark Founders. It provides a PAAS on AWS Cloud to solve complex Data problems. Databricks comes with an End to End Data Infrastructure wherein it manages Spark compute clusters on AWS EC2 along with managing Job Scheduling via Jobs, Model Training, Tracking, Registering and Experimentation via MLFlow and Data Versioning via Delta Lake.
Databricks as an organization has open sourced multiple ground-breaking services including -
- Apache Spark - http://spark.apache.org/
- MLFlow - https://mlflow.org/
- DeltaLake - https://delta.io/
Along with these Databricks also provide state of the art support for -
- Redash (Data Visualization Company acquired by Databricks recently) - https://redash.io/
- Tensorflow - https://databricks.com/tensorflow
- Koalas - https://koalas.readthedocs.io/en/latest/
Now, let’s jump to see how Databricks setup is done on AWS and how it helps to solve your data problems.
Architecture
Databricks provides a shared responsibility Model to its customers, wherein their Frontend UI (Control Plane) runs in their own AWS Account and Spark Compute Clusters (Data Plane) runs in Customer’s AWS Account.
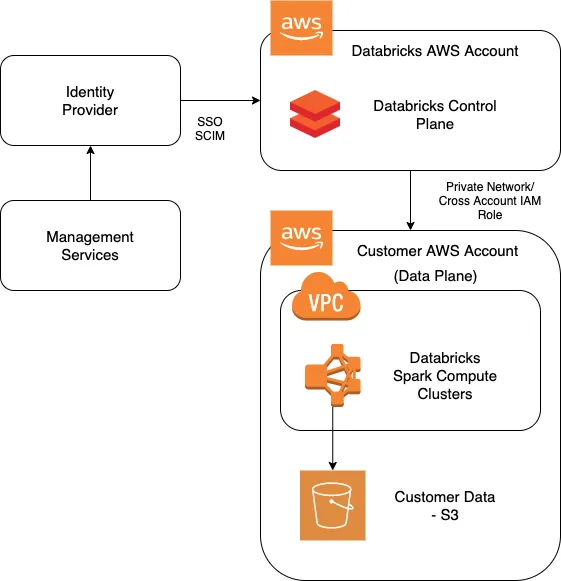
Setup Databricks on AWS
To setup Databricks on AWS, we need to follow following documentation from Databricks - Databricks Setup
After successful completion of all the steps highlighted in the official documentation, we will have Databricks running with a custom name as <random_name>.cloud.databricks.com
Databricks Clusters
Databricks is designed and developed to handle Big Data. Within Databricks we can create Spark clusters which in the backend spin up a bunch of EC2 machines with 1 driver node and multiple worker nodes (Worker Nodes are customizable and are defined by the user). In AWS, Databricks provides the functionality to create clusters using Spot Instances which further helps to reduce our compute cost by large numbers.
Within Databricks we can create a cluster using either UI, CLI or Rest APIs. In all cases, it invokes an API call to Clusters API. Official documentation -
https://docs.databricks.com/dev-tools/api/latest/index.htmlhttps://docs.databricks.com/dev-tools/api/latest/clusters.html
Let’s now jump on to Cluster creation within Databricks.
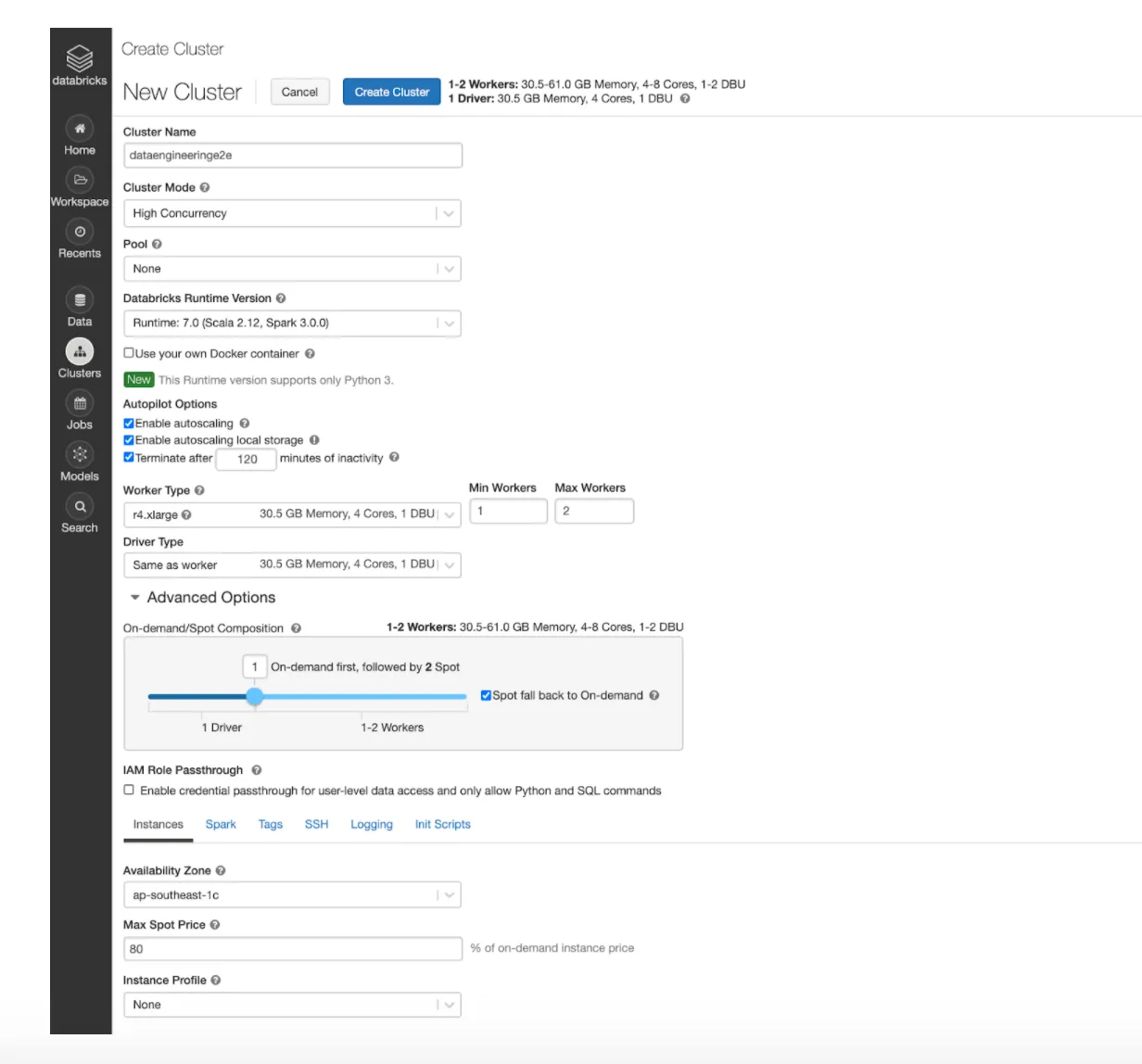
Creating Databricks Spark Cluster via UI
Input Variables -
- Cluster Name : Any user friendly name
- Cluster Mode : Databricks provide 2 types of Cluster Mode named High Concurrency and Standard. The difference between the two are - if multiple users are connected to a single cluster to run their jobs, it’s recommended to use High Concurrency Mode as in this case Databricks takes care of fair scheduling, resource allocation to each user per job etc. If it’s a single user, we can simply use Standard Cluster mode
- Pool : Databricks provides a feature called Pools. A user can create a pool of machines which can be up and running as per desired configuration and can help to speed up the cluster creation time or autoscaling time
- Databricks Runtime Version : This is the most important feature which basically governs your Spark version and corresponding libraries
- Availability Zone : AWS Availability Zone where you want to create your cluster
- Max Spot Price : If you’re using Spot Instances in your cluster, you can use this feature to bid for your spot machines.
- Instance Profile : In AWS Databricks Clusters use IAM Roles to interact with other AWS services like S3, DynamoDDB, RDS etc. We need to create an IAM Role with required permissions and import it within Databricks. Post that we can simply pass the Instance Profile of the role to be used with your cluster
Databricks provides a feature called Databricks Container Services (DCS). This is Databricks’ way of handling Docker Images. We can use DCS to package our libraries and pass it to our cluster which in further will load all the libraries as mentioned in the image during cluster creation time. With DCS, we can load the image from either ECR, ACR or Dockerhub.
To use an ECR Image, we need to check the “Use your own Docker container” option. Choose Authentication Mode as “Default”. With default option, your cluster will use IAM Instance Profile permissions to pull the image from ECR.
Enter the entire ARN of the Docker Image from ECR
AWS_Account_ID.dkr.ecr.ap-southeast-1.amazonaws.com/dataengineeringe2e:latest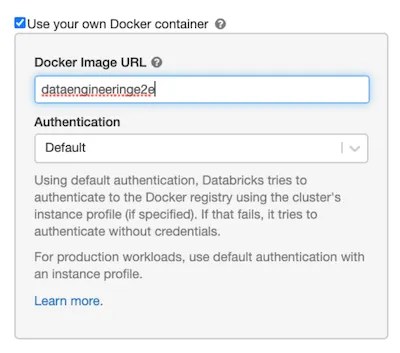
Within Databricks we can also pass our own Spark configuration to the cluster along with environment variables at cluster creation time. We need to add these values in Spark Config tab on the UI.
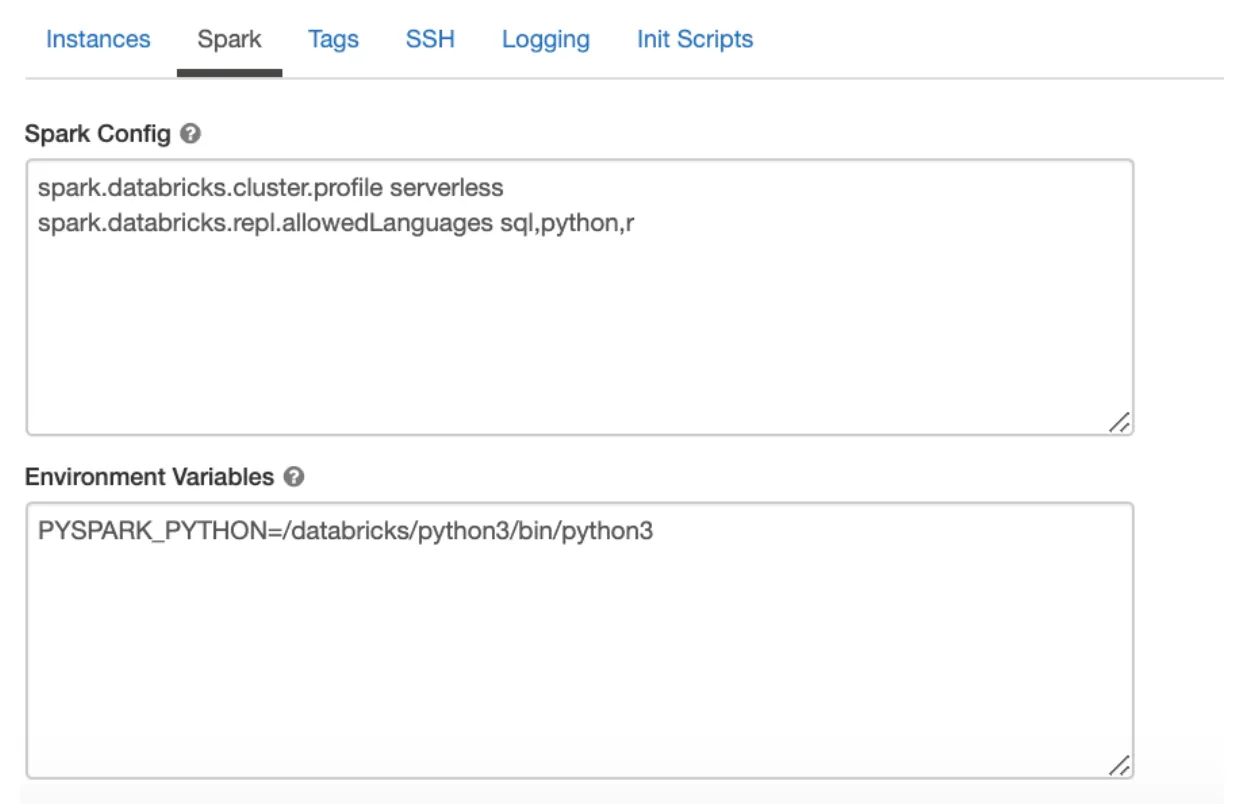
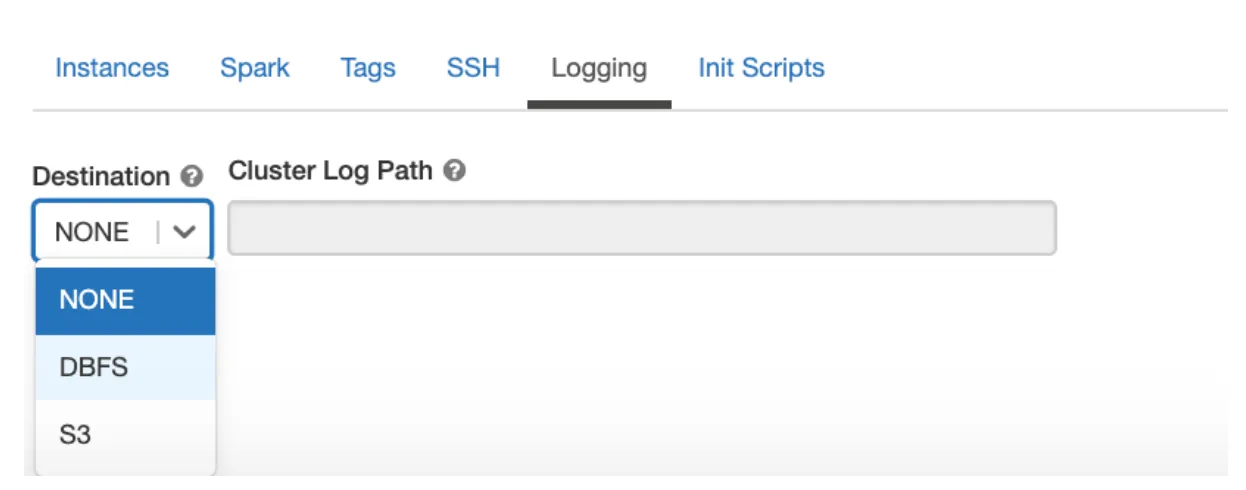
We can also add Cluster Level Logging, so that all our logs are saved permanently at a location as defined by the user - DBFS or S3.
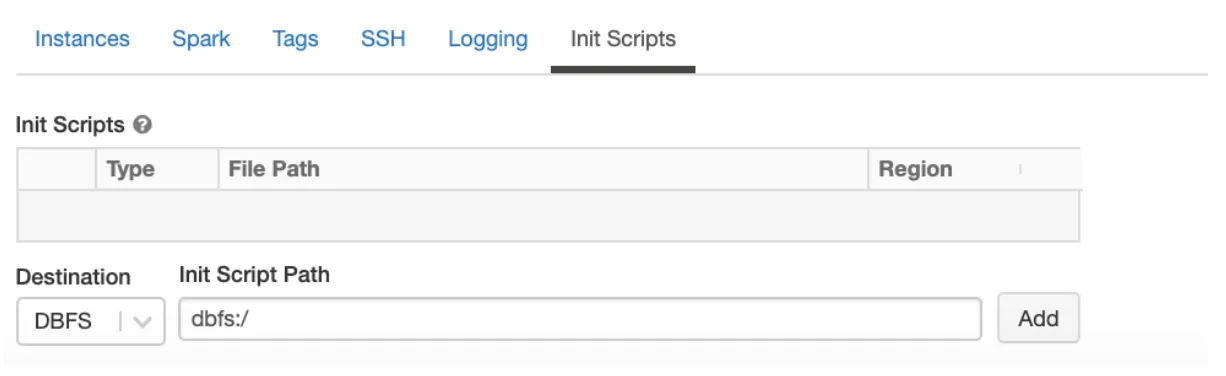
Init Scripts is Databricks’ way of managing libraries. If a user does not want to use DCS (Docker Container) to manage his/her libraries, he/she can make use of Init Scripts. These are simply Shell scripts that reside in DBFS and can be executed at Cluster creation time.
Create Databricks Spark Clusters via CLI or Rest API
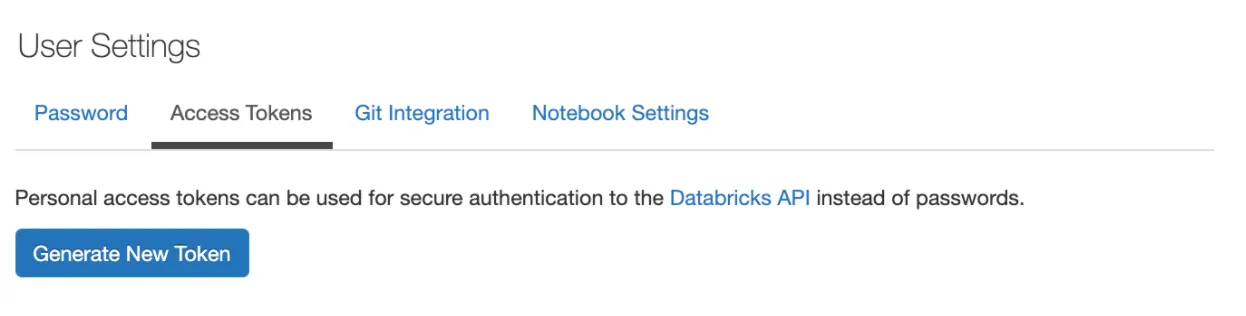
Firstly, we need to generate a Databricks Access Token. Official documentation for the same is below - Databricks CLI Authentication
Once we have generated a token, we need to Install and Configure Databricks CLI. Official documentation with steps to install Databricks CLI is below - Databricks CLI Install
After Databricks CLI is set up correctly we can simply create our Cluster using the following JSON. The JSON mentioned here contains exactly the same information that we inputted while creating the cluster via UI.
{
"num_workers": null,
"autoscale": {
"min_workers": 1,
"max_workers": 2
},
"cluster_name": "dataengineeringe2e",
"spark_version": "7.0.x-scala2.12",
"spark_conf": {
"spark.databricks.cluster.profile": "serverless",
"spark.databricks.repl.allowedLanguages": "sql,python,r"
},
"aws_attributes": {
"first_on_demand": 1,
"availability": "SPOT_WITH_FALLBACK",
"zone_id": "ap-southeast-1c",
"instance_profile_arn": "arn:aws:iam::<AWS_Account_ID>:instance-profile/dataengineeringe2e-role",
"spot_bid_price_percent": 80,
"ebs_volume_type": "GENERAL_PURPOSE_SSD",
"ebs_volume_count": 1,
"ebs_volume_size": 100
},
"node_type_id": "r4.xlarge",
"ssh_public_keys": [],
"custom_tags": {
"ResourceClass": "Serverless"
},
"spark_env_vars": {},
"autotermination_minutes": 120,
"enable_elastic_disk": true,
"init_scripts": [],
"docker_image": {
"url": "<AWS_Account_ID>.dkr.ecr.ap-southeast-1.amazonaws.com/dataengineeringe2e:latest"
}
}Cluster Creation CLI command -
databricks clusters create —json-file path_to_json_file