This article is a continuation to my previous article on how I built a Data Platform - On-Premise on Kubernetes. To further explain how Kubernetes works On-Premise and how we create Persistent Volumes, I’ll try to explain it through an example of how I deployed JupyterHub for our Data Scientists and Data Engineers.
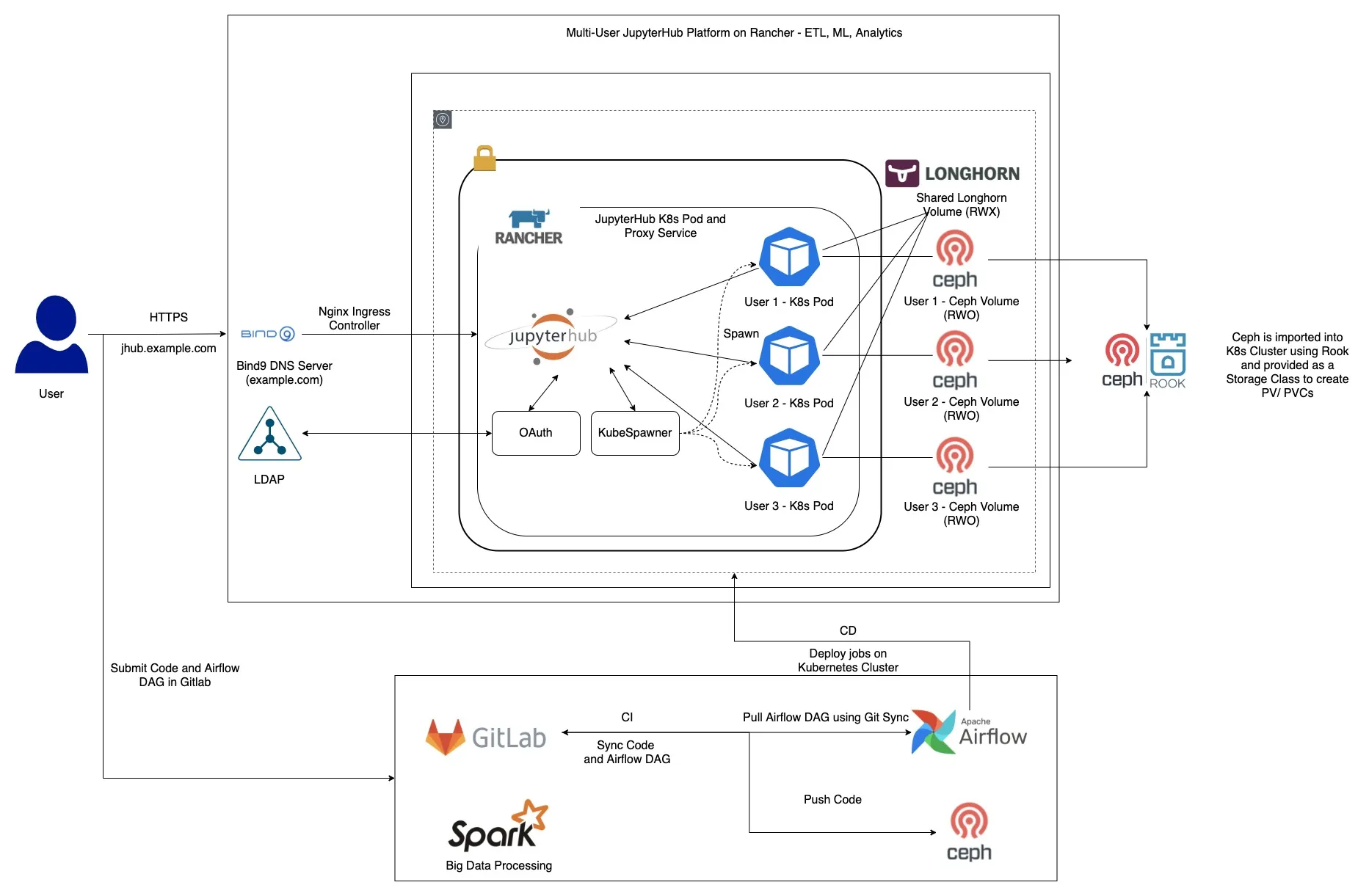
As you can see above, this is the high level overview of how JupyterHub can be run On-Premise seamlessly the same way it runs on AWS EKS. Our Data Scientists and Data Engineers once connected to VPN, can easily connect to JupyterHub through their browser. Our VPN server is configured to reach our DNS server managed by Bind9. Since we run JupyterHub on Kubernetes, it leverages KubeSpawner to spin User Pods. Our user pods are backed by Persistent Volumes created using Ceph. We used Rook Ceph to import our Ceph cluster within Kubernetes and created a storage class backed by it, which provides the functionality to create PVCs for our services. All our PVCs created by Ceph are of Access Mode RWO (Read Write Once) which means at any given point of time only a single pod can be mounted to the volume. Since we also wanted to create a shared volume, so that our users can share their work among each other, we decided to use Longhorn for this. It’s a Distributed Storage created by Rancher for Kubernetes. Longhorn provides us the functionality to create PVCs of type RWX (Read Write Many), which acts as a shared volume mounted to all user pods.
The general workflow is once an ETL job is ready to be productionise we commit the PySpark job to GitLab along with the Airflow DAG which in further is scheduled for periodic runs. Our Gitlab CI pipelines take care of the whole CI/CD process.
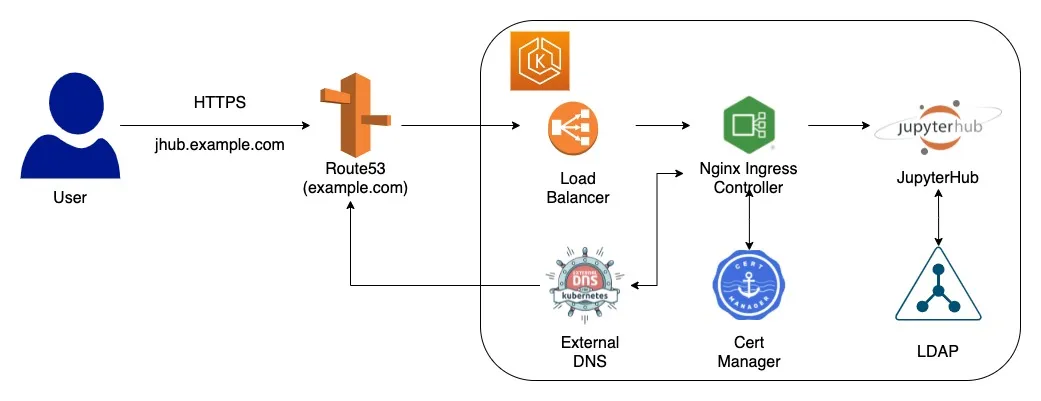
Now, if you must be wondering how DNS resolution works On-Premise for Kubernetes, so we set it up like below -
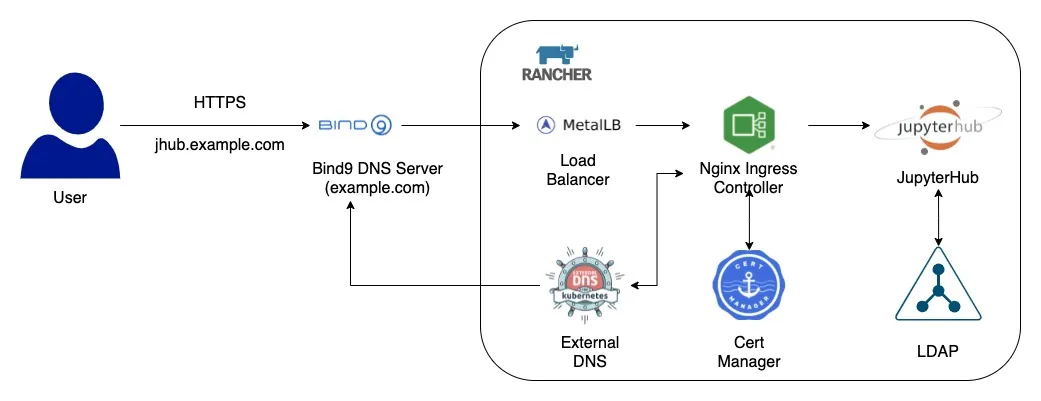
Once the user accesses the url through their browser, that request goes to our DNS Server (Bind9). In our DNS server we already have records present of how to route the request further down to our K8s Cluster. These records are automatically added to our DNS server with the help of External DNS running in our cluster. While setting up JupyterHub on our cluster, I also created an Ingress for it, so that we can access the service outside of our cluster. The DNS is resolvable over HTTPS due to the Cert Manager. I annotate our ingress configuration to generate Self Signed certificates with the help of Cert Manager.
I hope this gives a bit of idea on how to run JupyterHub On-Premise.
JupyterHub on EKS is also deployed in a similar way with a few tweaks here and there in the services we use. Below is an overview of how to run JupyterHub on AWS EKS.
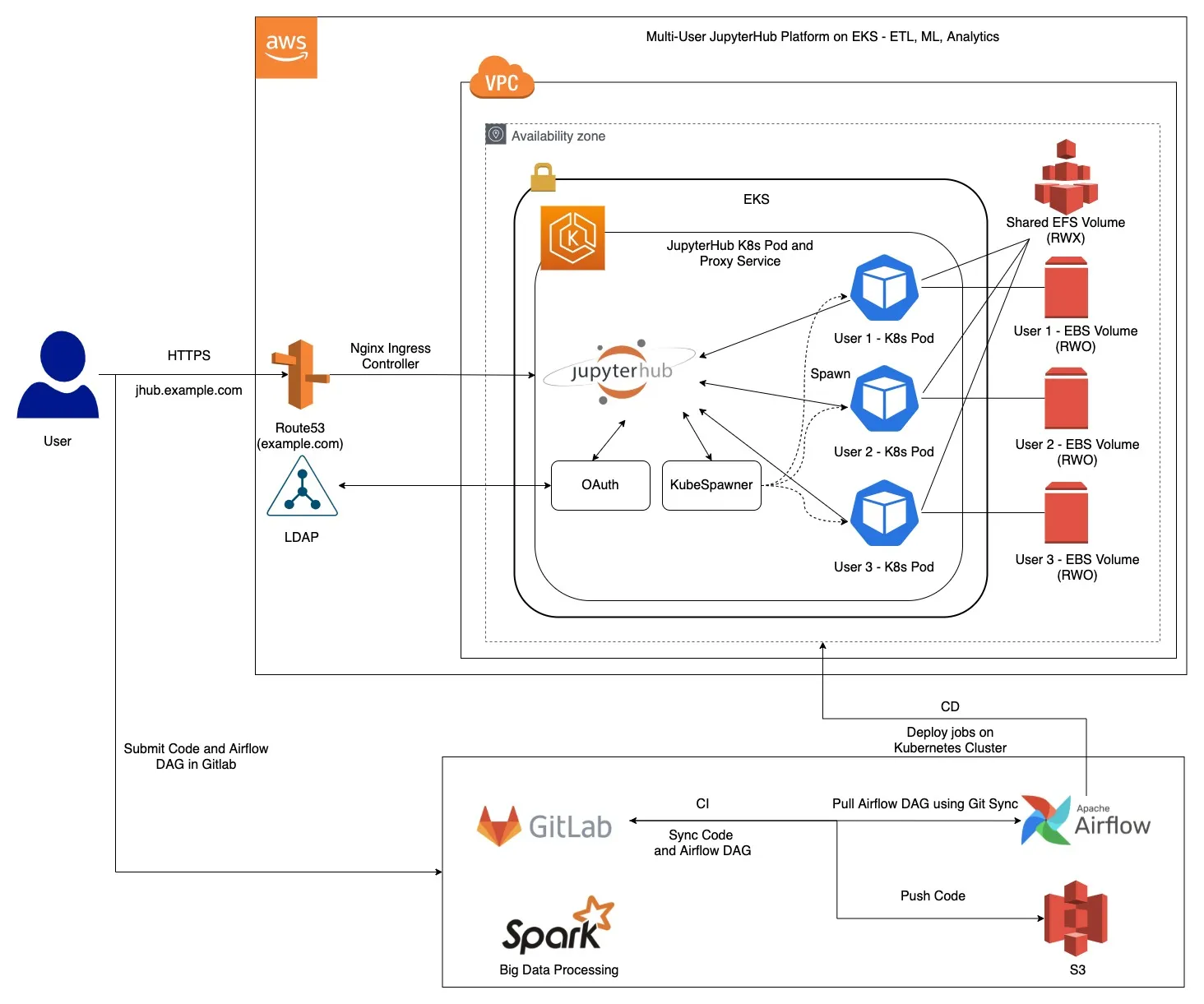
Now, if you must be wondering how DNS resolution works on AWS EKS, so we set it up like below -